情報理工学科の吳里奈助教とTad Gonsalves教授は、著名な画家ごとの絵画のスタイルについての情報を効率的に抽出し、効率よく高精度に変換できるモデルを開発しました。提案した画像変換手法は、GPUの計算コストを低く抑えることができるため、専用の計算機器だけでなく、スマートフォンなどの小型デバイス上でも実行することができます。
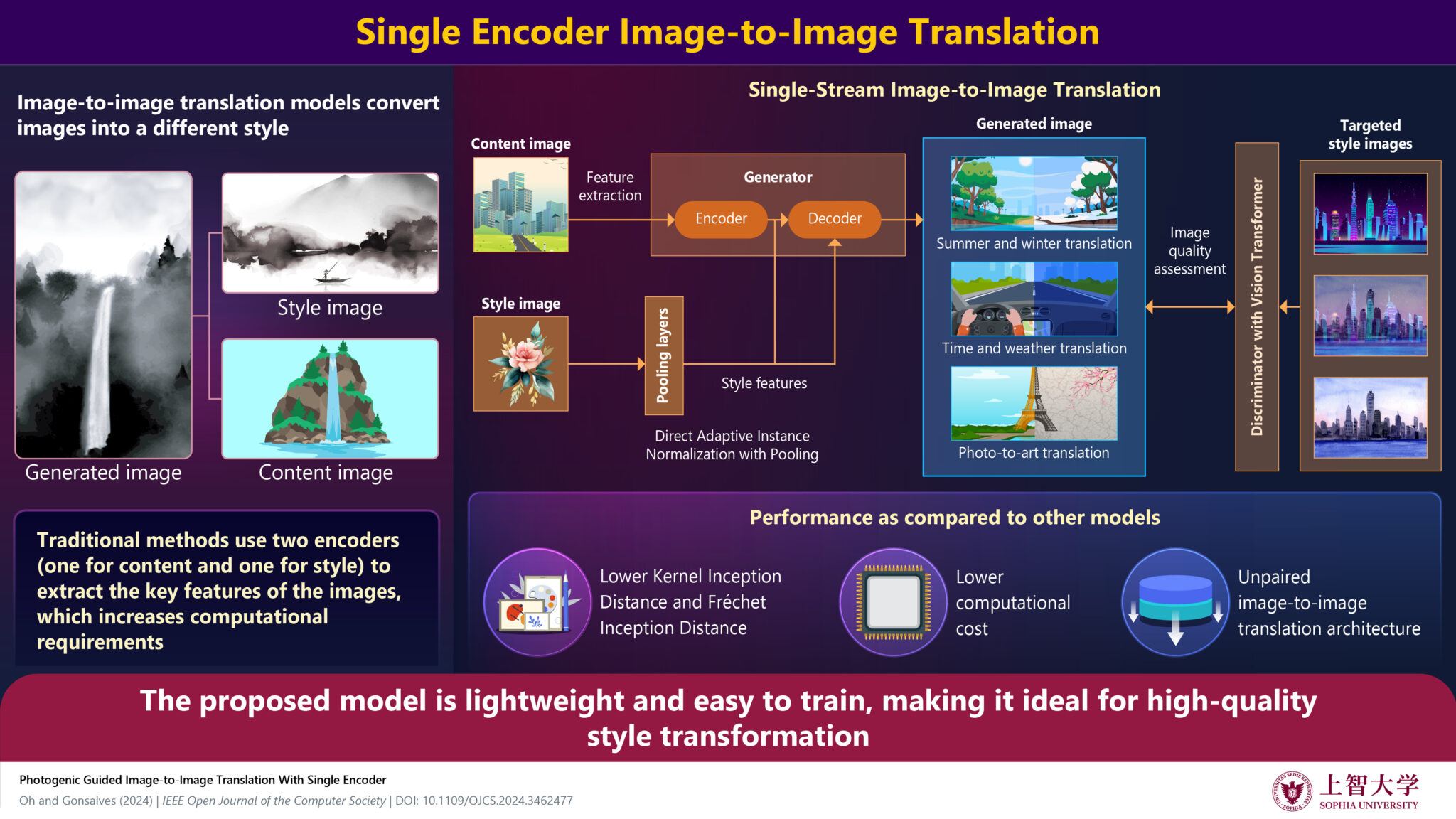
芸術分野において、「異なる時代の異なる作風を持つ画家が同じ景色を描いた場合、どのような絵画になるか」という比較ができれば、や各画家の技法などについての理解がより深まると期待されます。そこで本研究では、深層学習を用いて、異なるスタイルとコンテンツ(描かれて/映っている対象物)を組み合わせて、新たな画像を生成するモデルを開発しました。このモデルはプーリング(*1)および変形可能な畳み込み(Deformable Convolution, *2)を用いることで、特別なエンコーダを必要とせず、単一のエンコーダで、入力した画像から直接スタイルの特徴を抽出することができます。
提案したモデルを用いて、画像の季節の変換、天候に基づく環境変換、写真からアート作品への変換など、さまざまなタスクをテストしました。その結果、本モデルは、特に写真からアート作品への変換において、色の特徴を忠実に再現し、スタイル画像のデザイン情報を反映できることが示されました。さらに、生成された画像の品質を評価するFréchet Inception Distance (FID)およびKernel Inception Distance (KID)スコアから、本モデルは最先端の画像変換モデルを上回る性能を持つことが示唆されました。
本モデルは、作品間の技法の違いを比較・分析する新たな手法の開発につながる成果であり、これを活用することで、絵画作品や画家に関する研究の新たな可能性を拓くと期待されます。
本研究成果は2024年9月25日に国際学術誌「IEEE Open Journal of the Computer Society」にオンライン掲載されました。
敵対的生成ネットワーク(Generative Adversarial Network; GAN、*3)を用いた画像変換アーキテクチャは、セグメンテーション画像から実世界(real world)画像への変換、ある天気パターンから別の天気パターンへの変換、実世界の写真から芸術的画像への変換、画像や動画の超解像技術などにおいて、有望な結果を示しています。特に、CycleGAN(*4)のような、訓練時にペアとなる画像を必要としないアルゴリズムの導入により、画像変換の深層学習技術は急速に発展してきました。
吳助教は、CycleGANを用いて、ペア画像がなくてもコンテンツ画像からモネ風の絵画への変換に成功した先行研究などに着想を得て、深層学習モデルがクリエイティブなタスクにおいて高いパフォーマンスを発揮すると確信し、画家ごとの多様なスタイルへの変換を可能にする画像変換モデルの構築に取り組みました。
これまでに提案されたほぼすべての既存のガイド付き画像変換アーキテクチャは、入力に対して複数のエンコーダを使用しますが、このアーキテクチャは、入力コンテンツ画像に対して単一のエンコーダのみを使用する点が大きな特徴です。本研究では、提案したモデルの実装に向けて、計算コストと生成された画像の品質の評価も行いました。
研究チームは、コンテンツ画像の空間的特徴とスタイル画像の芸術的特徴を処理するために、プーリングを伴う新しい正規化関数を開発しました。この関数を用いることで、スタイル画像をより効果的に抽出し、既存の画像変換モデルよりも計算コストを削減することに成功しました。
さらに、空間特徴全体を分析するために、識別器にVision Transformer (ViT, *4)を採用しました。今回開発した新しいアーキテクチャを用いて、季節の変換、天候に基づく環境の変換、写真からアート作品への変換など、さまざまなタスクでテストを行いました。提案モデルは、特に写真からアート作品への変換において、色の特徴を忠実に再現し、スタイル画像のデザイン情報を高い精度で反映した画像を生成することができました(図)。なお、スタイル画像としては、ピサロ、モネ、マティス、ピカソ、セザンヌ、ゴーギャン、ルノワール、スタジオジブリ、浮世絵、ゴッホの10種のアートスタイルを用いました。
さらに、実画像と生成された画像の間の特徴の類似性を評価する基準であるFIDとKIDを用いて、本モデルの評価を行いました。その結果、提案したモデルは各実験において、比較対象である最先端の画像変換モデルを上回る性能を示しました。
研究を行った吳助教は、「今回開発したモデルを用いることで、『異なる画家が同じコンテンツを描いたとしたらどのような作品になるのか』という問いに対して、属人性の低い答えを出すことができます。これにより、単なる時代背景の考察を越えて、画家ごとの作風や技法の違いを比較・分析することが可能になると期待されます。また、今回提案した画像変換モデルは、計算コストが低く、スマートフォンなどの小型デバイスでも実行できるので、広く活用できるものと思います」と、本研究の意義を語っています。
なお、本研究で提案したモデルはGithubで公開しています。
https://github.com/rkomatsu2020/SSIT2023
*1 プーリング: 畳み込みニューラルネットワークにおいて、規則に従って更なる特徴量抽出を行う処理。
*2 変形可能畳み込み(Deformable Convolution): 畳み込みニューラルネットワークにおいて、一般的な畳み込みが正方形領域を対象とするのに対し、入力の状況に応じて畳み込み対象領域を自由に決定できる畳み込み方式のこと。
*3 敵対的生成ネットワーク(Generative Adversarial Network; GAN): 深層学習による画像生成アーキテクチャの一つ。生成ネットワークと識別ネットワークの2つのネットワークから構成され、生成ネットワークは識別ネットワークを欺く方向に学習し、識別ネットワークは生成ネットワークが生成した画像を正確に識別する方向に学習する。2つのネットワークが競争することにより、性能が向上する。
*3 CycleGAN: GANをさらに発展させた機械学習アルゴリズム。通常のGANでは識別ネットワークは生成された画像が本物かどうか識別するだけだが、CycleGANではさらに、生成された画像を元の画像に再変換した画像を元の画像と一致するように学習する。
*3 Vision Transformer (ViT): 自然言語処理で開発されたモデルTransformerを画像認識に適用したモデル。入力された情報を並列処理でき、機会学習のスピードが速く、精度も高い。
媒体名:IEEE Open Journal of the Computer Society
論文名:Photogenic Guided Image-to-Image Translation With Single Encoder
オンライン版URL:https://doi.org/10.1109/OJCS.2024.3462477
著者:Rina Oh, Tad Gonsalves
情報理工学科
助教 吳里奈 (E-mail:rina_oh@sophia.ac.jp)
上智学院広報グループ
sophiapr-co@sophia.ac.jp










 物質生命理工学科
物質生命理工学科
 機能創造理工学科
機能創造理工学科
 情報理工学科
情報理工学科